Basic SQL
Now you know the basic structure of a DB, the principle to designate different aspects of information into tables to keep them nice and tidy, what data type to choose for each kind of information, and how to cluster the tables appropriately for performance gain. It’s time to learn how to put these into a language DBMS understands, the Structured Query Language (SQL).
The syntax difference between SQL implementations are minor and we will use Microsoft T-SQL here.
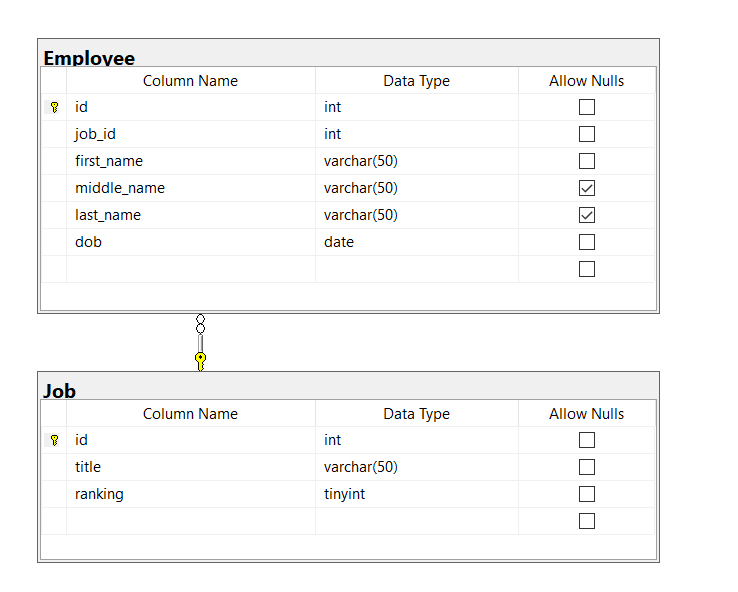
Say we want to design a DB to manage employees of the company. A company has different job positions, each with a title and rank. For employees of the company, we want to record their job position, their name, as well as their date of birthday. Note that there’s a 1-many relationship, where different employees can do the same job:
Create Table
CREATE TABLE Job (
id INT PRIMARY KEY
,title VARCHAR(50) NOT NULL
,ranking TINYINT NOT NULL
);
CREATE TABLE Employee (
id INT PRIMARY KEY
,job_id INT NOT NULL
,first_name VARCHAR(50) NOT NULL
,middle_name VARCHAR(50)
,last_name VARCHAR(50)
,dob DATE NOT NULL
,CONSTRAINT FK_Job_Id FOREIGN KEY (job_id) REFERENCES Job(id)
);
The result:
Alter Table Schema
-- add new column
ALTER TABLE Job ADD description VARCHAR(100) NOT NULL;
-- drop column
ALTER TABLE Job DROP COLUMN ranking;
-- alter column data type
ALTER TABLE Job ALTER COLUMN title VARCHAR(100);
Add Index
The two sample tables already have clustered index, the PK. In many scenarios, PK is a good clustered index candidate.
To add non-clustered index:
-- this non-clustered index also include the first_name, last_name columns' data to save a further table lookup
CREATE NONCLUSTERED INDEX idx_job_with_name ON Employee (job_id) include (
first_name
,last_name
)
Insert/Delete/Update Data
insert
INSERT INTO Job
VALUES (
1
,'DM'
,'The chief Dungeon Master of the company'
);
INSERT INTO Employee (
id
,job_id
,first_name
,last_name
,dob
)
VALUES (
1
,1
,'Zhu'
,'Cheng'
,'1985-07-02'
);

Note that we can either specify the columns we are inserting value to, or simply provide values for every column.
update
UPDATE Employee SET dob = '1986-07-02' WHERE id = 1
delete
DELETE FROM Employee WHERE id = 1
Select and beyond
Basic Select
-- select [attributes or * for all] from [table name] (where [expression])
SELECT *
FROM Job
WHERE title = 'DM';
SELECT first_name
,last_name
FROM Employee
ORDER BY last_name ASC;
Joins
Select by it self is pretty straight forward. But very often we need information across multiple tables in an appropriately normalized DB. This is when joins come to play. Selecting from join result is selecting from a temporary table returned by the join operation. Therefore let’s see what the temporary table is like for each join operation.
First insert these data into the DB so we have something to actually show the join result:
INSERT INTO Job
VALUES (
2
,'Soldier'
,'Attack at the DM''s command'
)
,(
3
,'Scout'
,'Search for intruders'
);
INSERT INTO Employee
VALUES (
2
,2
,'Jia'
,'Bing'
,'Song'
,'1989-01-02'
)
,(
3
,2
,'Yi'
,'Bing'
,'Song'
,'1993-11-17'
);
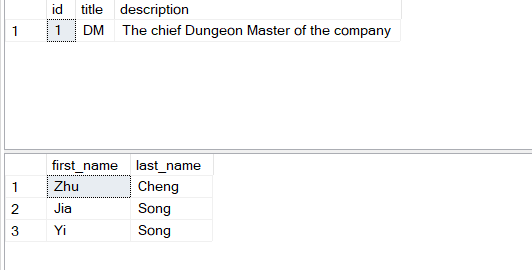
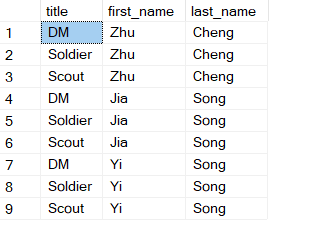
Now the data in the DB are:

Obviously the foreign key job_id is what’s connecting the two tables. Also note that there’s one job record “scout” that does not have any match in employee table yet.
inner join
Inner join includes data from both tables as long as they match.
SELECT j.title
,e.first_name
,e.last_name
FROM Job j
INNER JOIN Employee e ON j.id = e.job_id
Result:
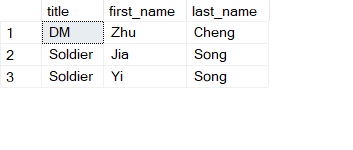
Note that the scout is missing from the result. This is because it does not have any matching employee yet.
left/right join
Left join is like inner join bit it guarantees that all data in the left table are included. If it cannot find for some rows in left table the matching rows in the right table, it’ll leave the value as null.
SELECT j.title
,e.first_name
,e.last_name
FROM Job j
LEFT JOIN Employee e ON j.id = e.job_id;
Result:
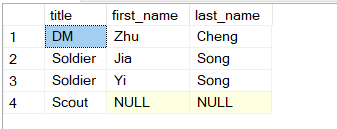
This time the scout is included although the right table does not have any matching result.
Right join works in a manner similar to left join.
full join
Full join is just the result from the left join plus the result from the right join.
SELECT j.title
,e.first_name
,e.last_name
FROM Job j
FULL JOIN Employee e ON j.id = e.job_id;
The result in our case should be the same as the left join.
cross join
Cross join includes every possible combination between the left table and right table, hence it’s also called Cartesian join because it’s just like a Cartesian product of two sets.
In cross join, the “on” part is missing because we don’t need attribute to connect the two table.
SELECT j.title
,e.first_name
,e.last_name
FROM Job j
CROSS JOIN Employee e;
Result:
Group
Another scenario where basic select does not satisfy our need is when data aggregation is required.
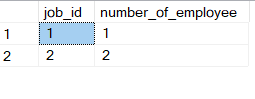
For example, what if we want to know how many employees are for each job? We have a employee table recording each employee and their job, but here we need to aggregate by counting how many rows there are for each job. T-SQL provide a nice aggregate function called count. What we really want here is to put all the employee records into groups based on their job, and count the number for employee in each group:
SELECT job_id
,count(*) AS number_of_employee
FROM Employee
GROUP BY job_id;
Result:
Of course we can use group along with joins:
SELECT j.title
,count(*) AS number_of_employee
FROM employee e
INNER JOIN Job j ON j.id = e.job_id
GROUP BY j.title;
Result:
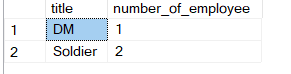
SP and Function
This post will not cover stored procedures and functions in detail but they are really useful and you already have all the tools you need at hand. SP and functions are just a bunch of SQL statements together to achieve a complex task, so you don’t have to manually type the statements every time. Instead, you create the SP or function and call it. The count function in the example above is a function provided by T-SQL.