这是小白网站架构的第二篇,点击这里阅读第一篇。
3. Web Application Servers (网站服务器)
如果不深究细节的话,网站服务器其实是比较容易描述的:服务器收到用户发来的请求,执行核心的业务逻辑,最终返回 HTML 给用户的浏览器。要做到这一点,服务器通常要和后端的一系列东西打交道,包括数据库、缓存层、工作队列、搜索服务、其他微服务、数据/日志队列等等。如前文所述,通常你会把至少两个 (往往更多) 服务器连上负载均衡,来处理用户请求。
服务器端的开发需要选定一门语言(Node.js, Ruby, PHP, Scala, Java, C# .NET 等) 和与之对应的 MVC 网络开发框架(如 Node.js 的 Express, Ruby on Rails, Scala 的 Play, PHP 的 Laravel)。但是具体到这些语言和框架的细节超出了本文的讨论范围。
4. Database Servers (数据库服务器)
如今每个网站都会用上一个或多个数据库来存储信息。数据库让你可以定义你数据的结构,插入新数据,找到已有数据,删改已有的数据,进行针对数据的计算,及进行其他操作。大部分情况下网站的服务器会直接连着一个数据库,任务服务器也一样。同时每个后台服务都有可能有它自己的专属数据库。
虽然我对架构中每个组件,都尽量避免进一步涉及到其具体技术。但对数据库我不得不往下多谈一点,那就是 SQL 和 NoSQL。
SQL 的意思是 “结构化查询语言 (Structured Query Language)”。它发明于 1970 年代,为广泛使用的关系型数据集提供了一个标准化的查询方式。SQL 数据库把数据存储在表 (table) 中,通过共有的 ID (通常为整数)把不同的表连接在一起。来看一个储存用户历史地址的简单例子:这里你可能会有两个表,分别叫 users 和 user_addresses,通过用户的 id 连接起来。请参考下面这个简单的示意图,user_addresses 里的 user_id 连接至 users 表,被称为 “外键” (foreign key)。
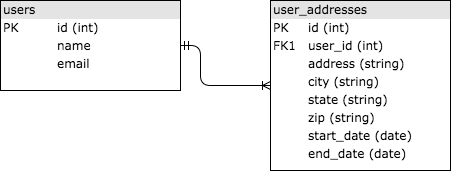
如果你不了解 SQL,我强烈推荐你学一下相关教程,如可汗学院上的这个。SQL 在网络开发中无处不在,所以你至少要懂得一些基本相关知识才能正确架构一个网站。
NoSQL (即非 SQL),是为了处理大型网站产生的海量数据而出现的一系列数据库技术。这是因为大部分 SQL 数据库都不能很好的进行横向规模化,其纵向规模化到一定程度也会碰上瓶颈。如果你还对 NoSQL 一无所知,我建议你从这些入门先有个大体认知:
- https://www.w3resource.com/mongodb/nosql.php
- http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
- https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
我还得提醒你一点:总的来说,即使在 NoSQL 的技术中,大家也往往是以 SQL数据库为中介。所以如果你不了解 SQL 你真的应该去学一学。目前基本没有什么办法能避免跟它打交道。
5. Caching Service (缓存服务)
缓存服务就是一个简单的「键值对」(key/value) 数据存储服务,让你有可能用接近 O(1) 的时间来存取信息。应用程序通常会用缓存服务来存储比较耗费资源的计算的结果,以避免下次需要时重复再计算。应用程序也可能缓存数据库查询结果,调用外部服务返回的结果,某个 URL 的页面,等等。下面是几个真实世界的例子:
- Google 会缓存一些常用搜索查询的结果,如“狗”,“Taylor Swift”, 而不是每次有人搜索时都重复计算。
- Facebook 会缓存你登入时看到的大部分数据,如帖子的,好友等。这篇文章详述了 Facebook 使用的缓存技术。
- Storyblocks 会缓存服务器端 React 输出的 HTML,及搜索结果,输入时的自动补全提示等。
最常用的两种缓存技术是 Redis 和 Memcache。我会在另一篇帖子里详细写它们。
6. Job Queue & Servers (工作队列与服务器)
大部分网站都需要在背后异步执行一些不是直接为了响应用户请求的工作。比如说 Google 需要爬取整个互联网,建立索引,将来才能返回搜索结果。它不会在你每次搜索时候干这件事,而是会选择异步的爬取网络,同时更新搜索索引。
有很多不同架构来实现执行异步任务,最常用的一种我称之为“工作队列”。它由两部分构成:一个由需要完成的“工作”组成的队列,及一个或多个工作服务器来执行队列中的工作。
工作队列储存了一个需要异步执行的工作的列表。最简单的就是先进先出 (first-in-first-out, FIFO) 队列,不过大部分应用最后都会在系统里加入一些优先级的机制。当应用需要执行一个工作时,不管这个工作是定时发生还是由用户行为出发的,应用所做的就是把这个工作加入队列中。
拿我们 Storyblocks 举例,我们使用了工作队列来驱动一些列幕后的日常任务 ,包括给视频和图片解码,处理 CSV 文件来给元数据加标签,汇总用户统计,发送密码重置邮件等等。一开始我们使用简单的先进先出队列,后来加入了优先级以保证一些对时间较敏感的任务,如发送密码重置邮件,可以尽快完成。
工作服务器来处理各种工作任务。它们查询工作队列,如果有下一个任务,就对队列取出一个来执行。我们可选用的语言和框架,与网络服务器一样众多,在这里也不再深入了。
7. Full-text Search Service (全文搜索服务)
绝大部分网络应用都会有搜索功能。用户输入一些文本 (一般称为 Query), 应用返回最相关的结果。这背后的技术通常就是所谓的「全文搜索」。这项技术会用到反向索引,来快速查询出包含所查询关键词的文档。

图中的例子展示了三篇文档的标题被转化成反向索引,用来实现从标题中的关键词到文档本身的快速查找。注意,常用的词诸如 “in”, “the”, “with” 等词,一般都不会被包含进反向索引中去。
虽然从数据库中也可能直接实现全文搜索(如 MySQL 就支持全文搜索) ,通常情况下都还是会运行一个单独的「搜索服务」。它负责计算并存储反向索引,并提供一个查询接口。目前最流行的全文搜索平台是 Elasticsearch,还有其他一些选择如 Sphinx, Apache Solr 等。
点击这里阅读第三篇